Abstract
The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.

Insights
-
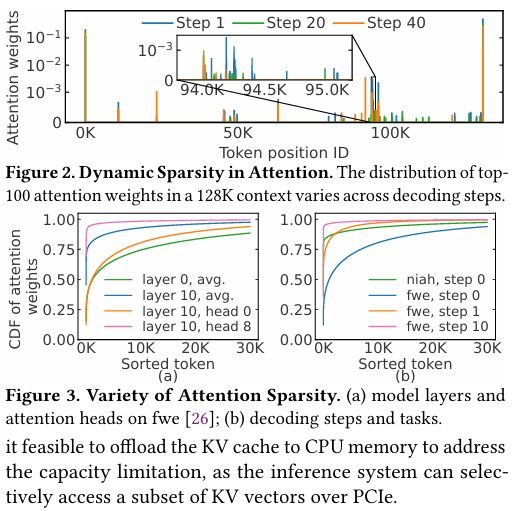
Attention sparsity makes it feasible to offload the KV cache to CPU memory to address the capacity limitation, as the inference system can selectively access a subset of KV vectors over PCIe.
-
Maximum Inner Product Search (MIPS), a variant of nearest neighbor search (NNS), can be seamlessly applied to identify critical tokens in attention mechanisms. This is due to the fact that high attention scores signify that their key vectors have a substantial inner product with the query vector.
-
We design wave index, an attention-aware vector index, to not only retrieve the important KV vectors accurately and efficiently, but also to do effective attention approximation to maintain the model accuracy as full attention. Wave index also leverages the spatial locality inherent in key-values to reduce the index construction overhead.
-
Sparsity alone is not a panacea. Based on the observation that decoding phase exhibits strong temporal locality, we design wave buffer, which efficiently manages the KV cache across GPU and CPU memory and caches hot KV vectors in GPU memory to reduce the data transfer over PCIe.
Why RetroInfer?
Utilizing attention sparsity is challenging for three reasons
:
(1) important tokens (i.e., those with high attention
weights) are scattered across the context, making their
positions unpredictable;
(2) tokens that are important at one decoding step
(i.e., one query vector) may not remain so in subsequent steps
;
(3) the sparsity exhibits high
variability from two sources: the architecture of the model itself and
the nature of the decoding query.
Previous works tend to rely on fixed-position heuristics to discard KV vectors or estimate
token importance by partioning the KV cache into equal-sized chunks and using chunk
representative vectors,
which often leads to significant loss due to static assumptions or low retrieval precision.
To address these issues, we present RetroInfer, an inference system that builds the KV cache as a vector storage system. We introduce an Attention-aW are VEctor index called wave index that retrieves the important KV vectors accurately and efficiently as needed, and a wave buffer which manages memory across the GPU and CPU to facilitate wave index, also in an attention-aware manner . Figure 1. shows the architecture of RetroInfer.
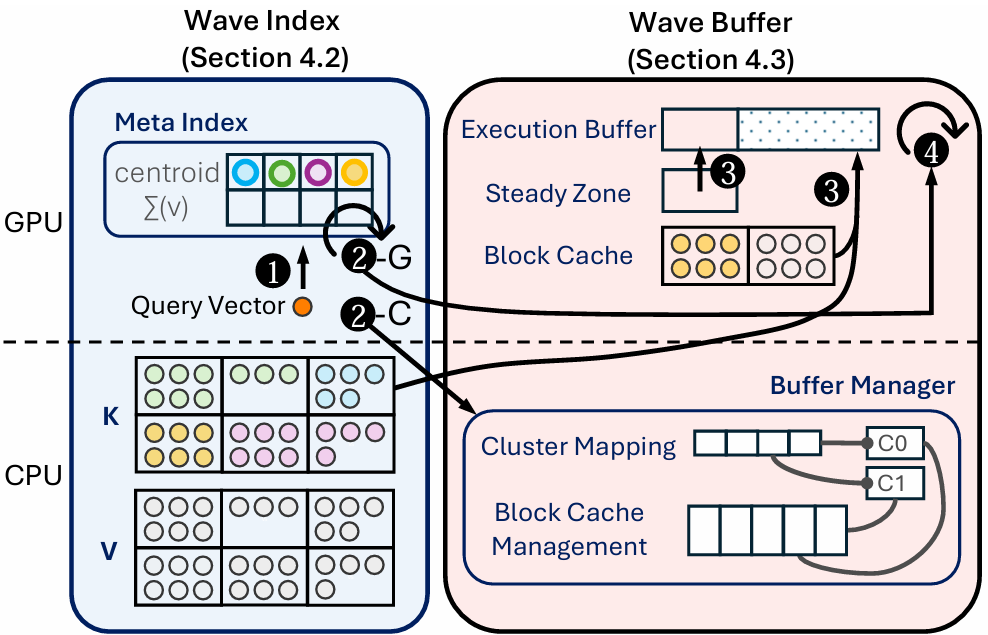
Figure 1. Architecture of RetroInfer. Circles with numbers represent the steps of attention computation, while steps with the same number occur in parallel. Colored circles indicate vectors. Centroids (bold-edged circles) are stored in the meta index.
To make judicious use of the GPU memory, the wave index employs a cluster-based vector index design. Specifically, wave index partitions the KV vectors into clusters based on their similarity and stores the centroids of the clusters in a meta index, as the representative of each cluster in GPU memory. The wave buffer serves two purposes. First, it contains several buffers in GPU memory to accelerate inference throughput. These include a block cache for KV vectors and an execution buffer , a dedicated memory region that sequentially arranges needed KV vectors for attention computation. The content of the execution buffer is copied from the steady zone, block cache, and directly from the CPU memory KV blocks in case of a cache miss. Second, a CPU-resident buffer manager that manages the block cache and data movement between GPU and CPU memory . Figure 2. shows the architecture of the wave index(left) and wave buffer(right).
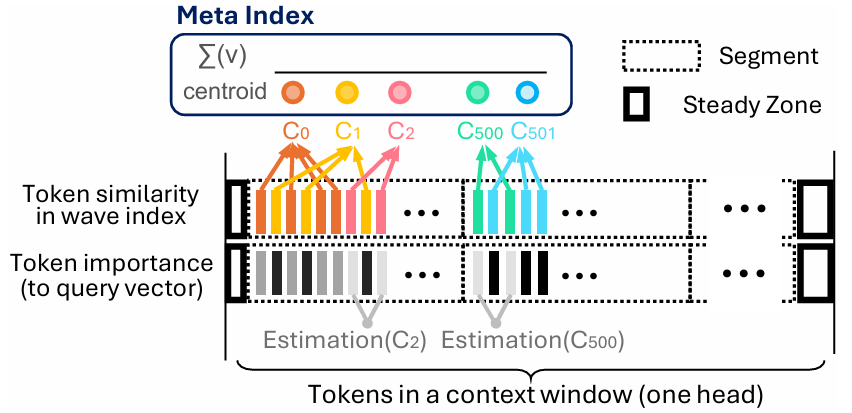
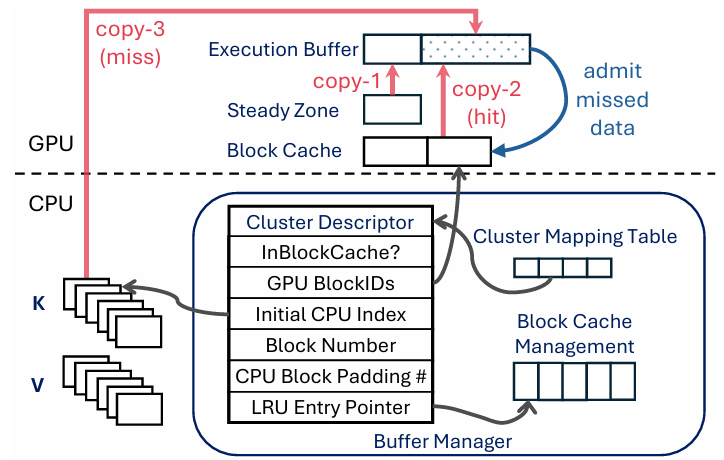
Figure 2. (left) Architecture of wave-index. Wave index divides the context into segments (dotted boxes). Each vertical bar represents a token at one position. In the first row, tokens with the same color belong to the same cluster, and similar colors (e.g., yellow and orange) indicate token similarity, which is based on key vector similarity. In the second row, the darker the bar, the more important the token to the query. (right) Architecture of wave-buffer. The black arrows indicate the pointer relationship between the data structures. The red arrows indicates the possible three source of data copy to ensemble the execution buffer. Missed data is admitted into the block cache by copying from the execution buffer (blue arrow).
During decoding, RetroInfer computes the attention for each head in parallel, following the steps in Figure 1.: (1): The centroids are sorted according to the similarity to the query vector, determining a subset of more critical clusters to retrieve for precise attention computation, and the clusters to perform estimation. (2): The GPU performs attention estimation (2-G), and a request is sent to the buffer manager to retrieve the needed clusters (2-C). execution buffer through parallel data copying. (3): The buffer manager ensures that the KV blocks are ready in the execution buffer through parallel data copying. (4): The GPU computes the precise attention using the KV vectors in the execution buffer, while the attention estimation (2-G) result is merged.
Our main contributions are four-fold:
-
We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference.
-
We introduce an Attention-aWare VEctor index called wave index that retrieves the important KV vectors accurately and efficiently as needed, and a wave buffer which manages memory across the GPU and CPU to facilitate wave index, also in an attention-aware manner.
-
We introduce tripartite attention approximation to ensure the accuracy of attention computation with reduced computation cost by leveraging both the properties of the attention mechanism and the advantage of vector retrieval.
-
We evaluate RetroInfer across three benchmarks: RULER, LongBench, and Needle in a Haystack, with token lengths ranging from 5k to 1M, to assess the inference accuracy and efficiency of LLMs. We demonstrate that RetroInfer not only achieves significant speedups over full and sparse attention baselines, but also preserves model accuracy.
Experiments Results in Long-context Benchmarks
We utilize three representative long-context benchmarks to evaluate the inference accuracy
of all systems: (1) RULER; (2) Needle-in-a-haystack (NIAH); (3) LongBench.
As shown in Table 1., RetroInfer consistently achieves better accuracy than other methods on
almost all tasks and matches the accuracy of full attention.
For the average task accuracy, RetroInfer has only a drop of
0.73%/0.78%/1.46% compared to full attention on
Llama3.1-8B/Qwen2.5-7B/Llama3-8B-1048K, respectively.
Compared to the best-performing sparse attention baselines on each model
(Quest/InfiniGen/Quest for Llama3.1-8B/Qwen2.5-7B/Llama3-8B-1048K),
RetroInfer achieves 5.48%/15.51%/3.33% accuracy improvements
, respectively.
| Methods | s1_niah | s2_niah | s3_niah | mk1_niah | mk2_niah | mk3_niah | mv_niah | mq_niah | fwe | cwe | qa_1 | qa_2 | vt | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama3.1-8B | 100.00 | 100.00 | 99.50 | 99.00 | 88.50 | 55.00 | 91.62 | 97.25 | 53.67 | 0.05 | 71.00 | 39.50 | 88.80 | 75.68 |
| Quest | 100.00 | 99.50 | 99.50 | 98.00 | 71.00 | 3.00 | 87.00 | 95.38 | 55.17 | 0.15 | 68.50 | 41.00 | 84.90 | 69.47 |
| MagicPIG | 99.00 | 97.50 | 92.00 | 98.50 | 73.50 | 26.50 | 77.25 | 94.62 | 53.00 | 0.05 | 65.50 | 37.00 | 86.50 | 69.30 |
| InfiniGen | 100.00 | 96.00 | 44.50 | 95.00 | 39.00 | 0.00 | 67.75 | 82.88 | 46.50 | 0.40 | 68.00 | 37.50 | 75.50 | 57.93 |
| RetroInfer | 100.00 | 99.50 | 100.00 | 99.00 | 83.00 | 38.50 | 92.88 | 97.38 | 64.00 | 0.10 | 70.50 | 40.50 | 89.00 | 74.95 |
| Qwen2.5-7B | 100.00 | 100.00 | 100.00 | 92.50 | 48.50 | 18.50 | 67.00 | 88.00 | 64.00 | 41.20 | 44.50 | 36.50 | 85.20 | 68.15 |
| Quest | 100.00 | 55.00 | 90.00 | 49.50 | 27.50 | 0.00 | 48.00 | 53.75 | 63.50 | 34.00 | 38.00 | 30.00 | 84.90 | 51.86 |
| MagicPIG | 92.50 | 62.50 | 37.50 | 54.50 | 25.50 | 3.50 | 42.00 | 46.00 | 65.33 | 38.40 | 40.50 | 33.50 | 80.50 | 47.86 |
| InfiniGen | 100.00 | 77.00 | 53.50 | 70.00 | 10.00 | 0.50 | 48.00 | 58.50 | 58.83 | 29.60 | 42.00 | 33.50 | 87.50 | 51.46 |
| RetroInfer | 100.00 | 98.50 | 99.50 | 93.00 | 47.00 | 15.50 | 65.25 | 84.50 | 58.67 | 42.25 | 46.00 | 38.50 | 87.20 | 67.37 |
| Llama3-8B-1048K | 100.00 | 100.00 | 100.00 | 98.50 | 99.50 | 66.50 | 96.00 | 98.75 | 75.50 | 0.75 | 64.50 | 47.00 | 79.80 | 78.98 |
| Quest | 100.00 | 100.00 | 100.00 | 99.00 | 92.50 | 14.50 | 98.00 | 99.00 | 67.33 | 3.00 | 63.00 | 44.50 | 83.70 | 74.19 |
| MagicPIG | 99.50 | 95.00 | 94.00 | 88.50 | 96.50 | 44.50 | 74.50 | 76.88 | 73.67 | 0.40 | 63.00 | 44.00 | 75.90 | 71.26 |
| InfiniGen | 100.00 | 99.50 | 98.50 | 97.00 | 88.50 | 15.50 | 91.75 | 91.88 | 63.83 | 0.80 | 62.50 | 45.50 | 80.00 | 71.94 |
| RetroInfer | 100.00 | 100.00 | 100.00 | 97.50 | 96.50 | 60.00 | 92.75 | 98.50 | 73.00 | 0.75 | 64.00 | 46.50 | 78.20 | 77.52 |
Table 1. Model Accuracy(RULER, 128K Context). RetroInfer significantly outperforms other methods and maintains the same accuracy level as full attention on three models.
To further evaluate the effectiveness of RetroInfer on more realistic tasks, we selected
five tasks from the LongBench benchmark for extensive evaluation.
As shown in Table 2., RetroInfer consistently outperforms all baselines, with average scores at most 0.23% lower than full attention
.
| Methods | QaS | GoR | TrQ | RbP | LCC | Avg. |
|---|---|---|---|---|---|---|
| Llama3.1-8B | 12.88 | 34.30 | 91.31 | 56.40 | 62.88 | 51.55 |
| Quest | 9.43 | 31.42 | 89.86 | 50.41 | 44.30 | 45.08 |
| MagicPIG | 12.00 | 33.18 | 90.80 | 55.50 | 61.14 | 50.52 |
| InfiniGen | 10.96 | 32.36 | 90.71 | 49.94 | 44.12 | 45.62 |
| RetroInfer | 12.31 | 34.71 | 91.33 | 56.15 | 62.10 | 51.32 |
| Qwen2.5-7B | 9.98 | 35.41 | 87.15 | 61.69 | 56.34 | 50.11 |
| Quest | 9.05 | 31.54 | 82.16 | 53.15 | 42.07 | 43.59 |
| MagicPIG | 9.87 | 34.00 | 86.35 | 60.25 | 55.43 | 49.18 |
| InfiniGen | 9.61 | 33.10 | 87.02 | 46.72 | 30.58 | 41.41 |
| RetroInfer | 9.77 | 34.76 | 87.33 | 61.80 | 55.76 | 49.88 |
| Llama3-8B-1048K | 14.25 | 35.25 | 87.06 | 44.74 | 45.18 | 45.30 |
| Quest | 11.22 | 30.35 | 86.94 | 44.84 | 36.74 | 42.02 |
| MagicPIG | 13.66 | 33.28 | 87.21 | 42.56 | 43.58 | 44.06 |
| InfiniGen | 12.15 | 30.81 | 85.39 | 38.84 | 29.41 | 39.32 |
| RetroInfer | 15.17 | 34.66 | 86.74 | 45.58 | 45.66 | 45.56 |
Table 2. Model Accuracy (LongBench). RetroInfer consistently outperforms all baselines and maintains the same accuracy level as full attention on three models.
Figure 3. (left) presents the average model accuracy
across context lengths from 8K to 128K on RULER on all models.
RetroInfer maintains its advantage
over others, showing the robustness of RetroInfer's attention
approximation
. Figure 3. (right) further demonstrates the accuracy of
RetroInfer
with context lengths up to 1M.
RetroInfer achieves 100% accuracy on all contexts,
demonstrating our system's capability to support million-token with accuracy.
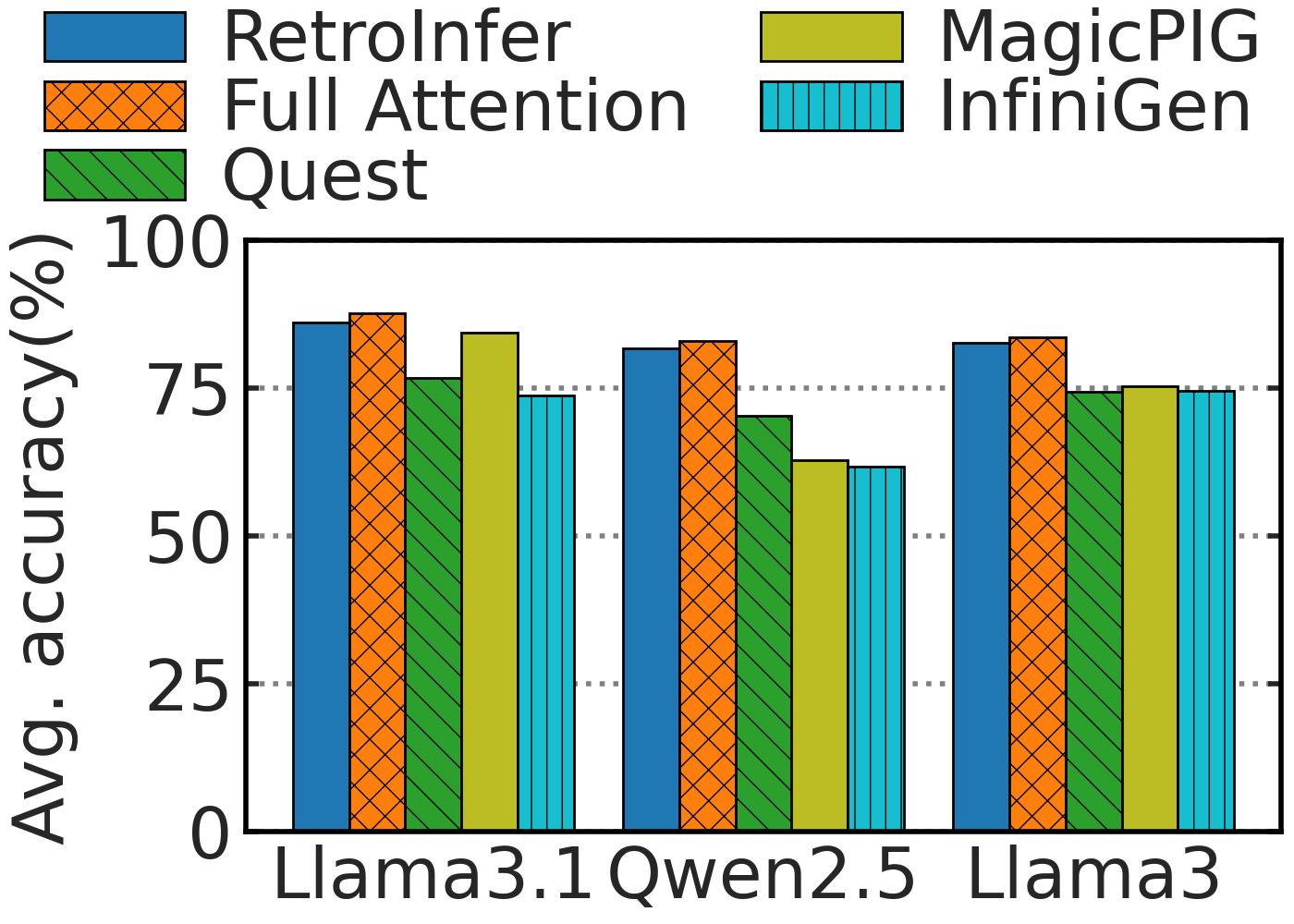
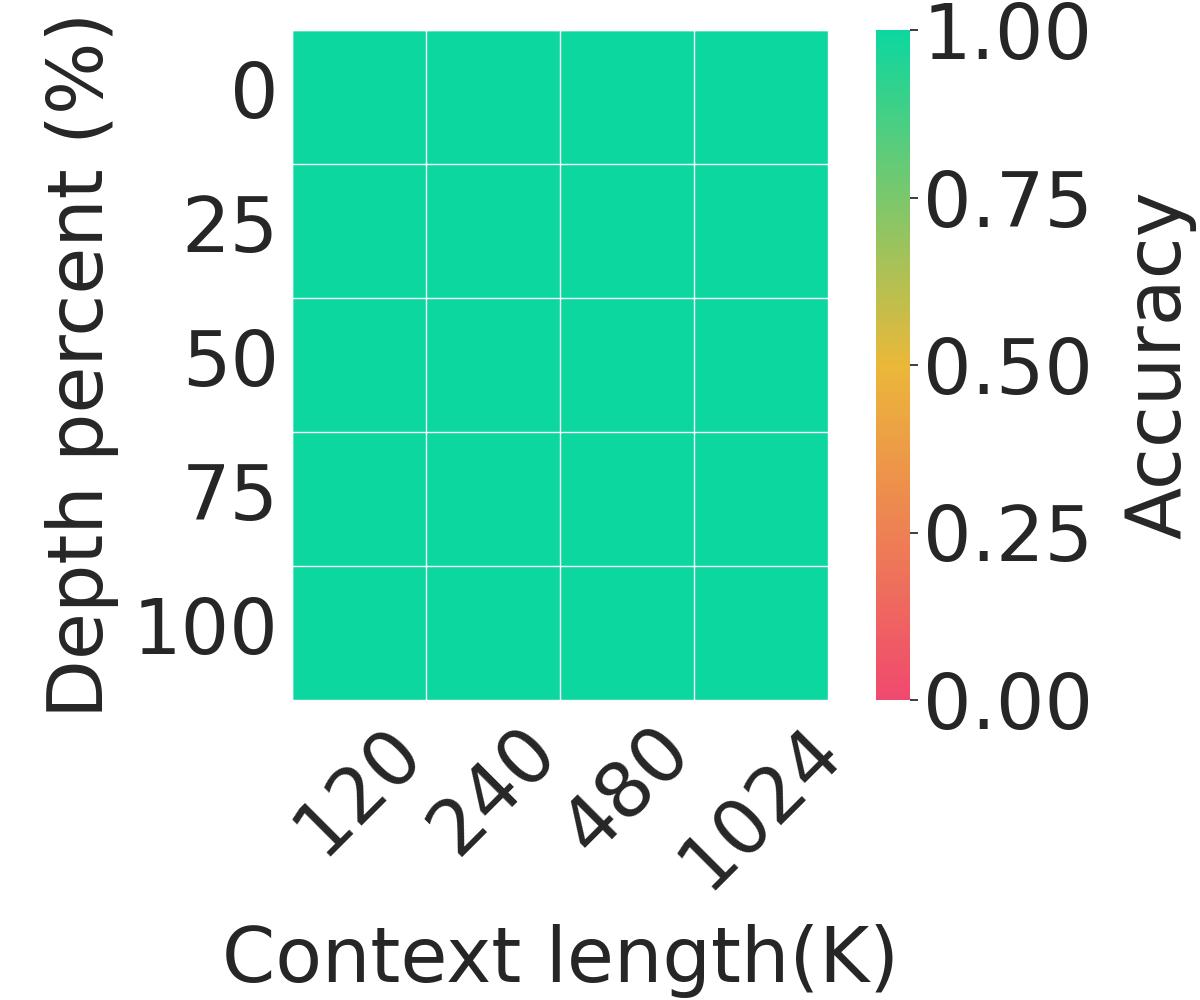
Figure 3. (left) Average Model Accuracy on RULER (8K to 128K Context) and (right) Needle-in-a-hay-stack (Llama3-8B-1048K).
Inference Efficiency
Throughput
Figure 4. shows the decoding through put of RetroInfer and other methods across four
different context lengths ranging from 60K to 1024K.
For the context length of 60K, 120K and 240K, RetroInfer
outperforms full attention by 4.4×, 4.4×, and 4.5×
respectively.
When compared with Quest, Quest (offload), MagicPIG and InfiniGen,
the speedups increase to 3.4×, 18.3×, 11.6×, and 76.9×,
with an average across three context lengths.
Combined with results in Figure 12 (a), RetroInfer achieves the best throughput while also
outperforming other baselines in terms of model accuracy.

Figure 4. RULER Accuracy and Decoding throughput vs. Context Length and Batch Size (Llama3-8B-1048K). (a) RetroInfer matches full attention accuracy and outperforms baselines across different context lengths. (b)-(e) RetroInfer scales well with the batch size and achieves the best throughput on all context lengths.
Prefilling Latency
Figure 5. shows that the prefilling latency of RetroInfer exceeds that of full attention by
only 7%, 4%, and 2% at context lengths of 120K, 240K,
and 480K, respectively.
Index building is much faster than full attention and becomes negligible at longer context
lengths.
This reduction stems from the quadratic cost of full attention compared to the lower complexity of segmented clustering and asynchronous wave
buffer construction.
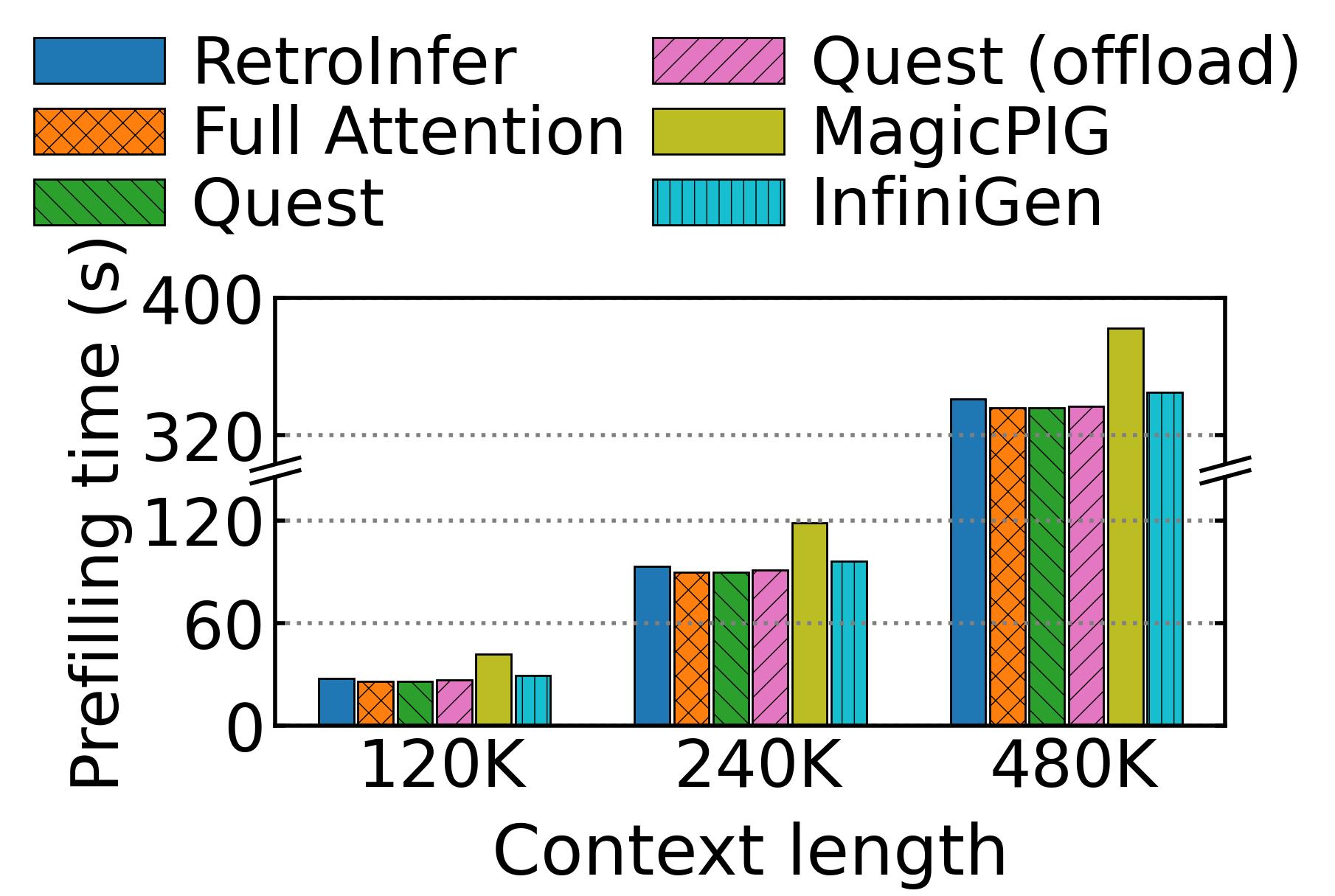
Figure 5. Prefilling Latency vs. Context Lengths (batch = 1). The prefilling latency of RetroInfer is only slightly higher than full attention, and the overhead becomes negligible as the context length increases.
BibTeX
If you find this project helpful, please cite the following papers:
@misc{chen2025retroinfervectorstorageapproachscalable,
title={RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference},
author={Yaoqi Chen and Jinkai Zhang and Baotong Lu and Qianxi Zhang and Chengruidong Zhang and Jingjia Luo and Di Liu and Huiqiang Jiang and Qi Chen and Jing Liu and Bailu Ding and Xiao Yan and Jiawei Jiang and Chen Chen and Mingxing Zhang and Yuqing Yang and Fan Yang and Mao Yang},
year={2025},
eprint={2505.02922},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.02922},
}